ITIC 2024 Hourly Cost of Downtime Part 2
There’s No Right Time for Downtime
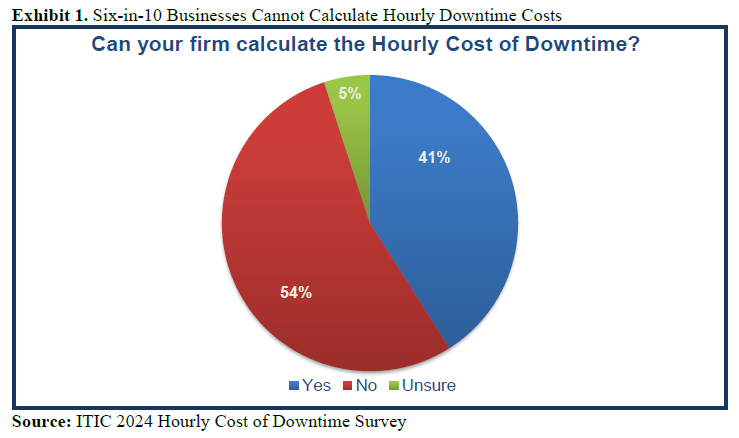
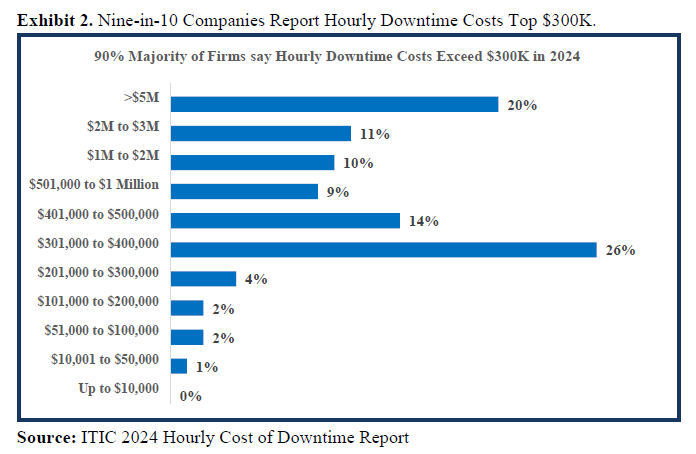
ITIC’s 11th annual Hourly Cost of Downtime Survey data indicates that 97% of large enterprises with more than 1000 employees say that on average, a single hour of downtime per year costs their company over $100,000. Even more significantly: four in 10 enterprises – 41% – indicate that hourly downtime costs their firms $1 million to over $5 million (See Exhibit 1). It’s important to note that these statistics represent the “average” hourly cost of downtime. In a worst-case scenario – such as a catastrophic outage that occurs during peak usage times or an event that disrupts a crucial business transaction – the monetary losses to the organization can reach and even exceed millions per minute.
Additionally, in highly regulated vertical industries like Banking and Finance, Food, Energy, Government, Healthcare, Hospitality, Hotels, Manufacturing, Media and Communications, Retail, Transportation and Utilities, must also factor in the potential losses related to litigation. Businesses may also be liable for civil penalties stemming from their failure to meet Service Level Agreements (SLAs) or Compliance Regulations. Moreover, for select organizations, whose businesses are based on compute-intensive data transactions, like stock exchanges or utilities, losses may be calculated in millions of dollars per minute.
ITIC’s most recent poll – conducted in conjunction with the ITIC 2023 Global Server Hardware Server OS Reliability Survey – found that a 90% majority of organizations now require a minimum of 99.99% availability. This is up from 88% in the last 2 ½ years. The so-called 99.99% or “four nines” of reliability equals 52 minutes of unplanned per server/per annum downtime for mission critical systems and applications or, 4.33 minutes of unplanned monthly outages for servers, applications, and networks.
All categories of businesses were represented in the survey respondent pool: 27% were small/midsized (SMB) firms with up to 200 users; 28% came from the small/midsized (SME) enterprise sector with 201 to 1,000 users and 45% were large enterprises with over 1,000 users.
These above statistics are not absolute. They are the respondents’ estimates of the cost of one hour of hourly downtime due to interrupted transactions, lost/damaged data, and end user productivity losses that negatively impacted corporations’ bottom line. These figures exclude the cost of litigation, fines or civil or criminal penalties associated with regulatory non-compliance violations. These statistics are also exclusive of any voluntary “good will” gestures a company elects to make of its own accord to its customers and business partners that were negatively affected by a system or network failure. Protracted legal battles and out-of-court settlements, fines and voluntary good-will gestures do take a toll on the company’s revenue and cause costs to skyrocket further – even if they do help the firm retain the customer account. There are also “soft costs” that are more elusive and difficult to measure, but nonetheless negative. These include the damage to the company’s reputation which may result in untold lost business and persist for months and years after a highly publicized incident.
To reiterate: in today’s Digital Age of “always on” networks and connectivity, organizations have no tolerance for downtime. It is expensive and risky. And it is just plain bad for business.
Only four (4%) percent of enterprise respondents said that downtime costs their companies less than $100,000 in a single 60-minute period and of that number an overwhelming 93% majority were micro SMBs with fewer than 10 employees. Downtime costs are similarly high for small and midsized businesses (SMBs) with 11 to 200 employees. To reiterate, these figures are exclusive of penalties, remedial action by IT administrators and any ensuing monetary awards that are the result of litigation, civil or criminal non-compliance penalties.
Do the Math: Downtime Costs Quickly Add Up
Downtime is expensive for all businesses – from global multinational corporations to small businesses with fewer than 20, 50 or 100 employees. Hourly losses of hundreds of thousands or millions per hour or even minutes in transaction-heavy environments are unfortunately commonplace. Exhibit 3 depicts the monetary costs of per server/per minute downtime involving a single server to as many as 1,000 servers in which businesses calculate hourly downtime costs from $100,000 to $10,000,000 million (USD).
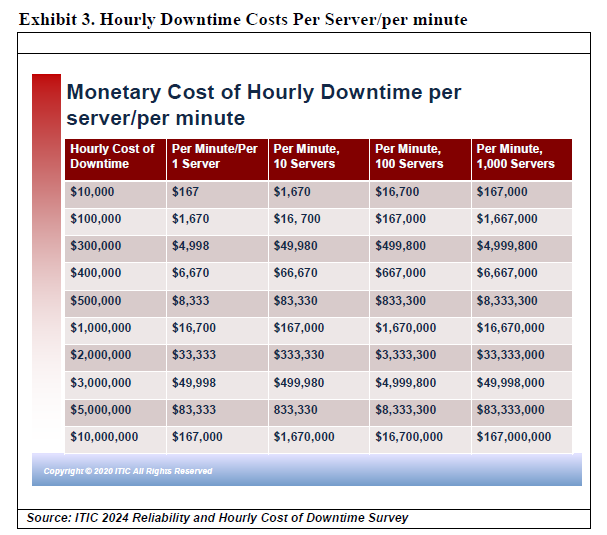
As Exhibit 3 illustrates a one minute of downtime for a single server in a company that calculates its hourly cost of downtime for a mission critical server or application at $100,000 is $1,667 and $16,670 per minute when downtime affects 10 servers and main line of business applications/data assets. The above chart graphically emphasizes how quickly downtime costs add up for corporate enterprises.
Small businesses are equally at risk, even if their potential downtime statistics are a fraction of large enterprises. For example, an SMB company that estimates that one hour of downtime “only” costs the firm $10,000 could still incur a cost of $167 for a single minute of per server downtime on their business-critical server. Similarly, an SMB company that assumes that one hour of downtime costs the business $25,000 could still potentially lose an estimated $417 per server/per minute. With few exceptions micro SMBs –with 1 to 20 employees – typically would not rack up hourly downtime costs of hundreds of thousands or millions in hourly losses. Small companies, however, typically lack the deep pockets, larger budgets, and reserve funds of their enterprise counterparts to absorb financial losses or potential litigation associated with downtime. Therefore, the resulting impact could be as devastating for them as it is for enterprise firms.
Hourly downtime costs of $25,000; $50,000 or $75,000 (exclusive of litigation or civil and even criminal penalties) may be serious enough to put the SMB out of business – or severely damage its reputation and cause it to lose business.
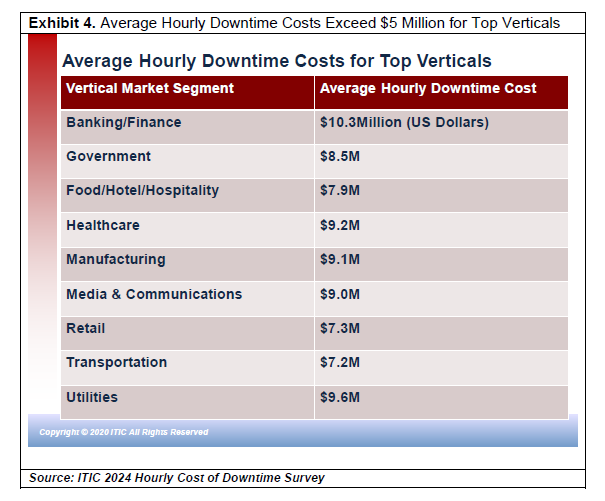
Hourly Downtime Costs Exceed $5 Million for Top Verticals
Exhibit 4 shows that ITIC’s Hourly Cost of Downtime survey revealed that for large enterprises, the costs associated with a single hour of downtime are much higher. Average hourly outage costs topped the $5 Million (USD) mark for the top verticals. These include Banking/Finance; Government; Healthcare; Manufacturing; Media & Communications; Retail; Transportation and Utilities.
Once again, except in specific and rare instances, in 2024, corporations have a near total reliance on their personal and employer-owned interconnected networks and applications to conduct business. Corporate revenue and productivity are inextricably linked to the reliability and availability of the corporate network and its data assets. When servers, applications and networks are unavailable for any reason business and productivity slow down or cease completely.
The minimum reliability/uptime requirements for the top vertical market segments are even more stringent and demanding than the corporate averages in over 40 other verticals as Exhibit 5 below illustrates.
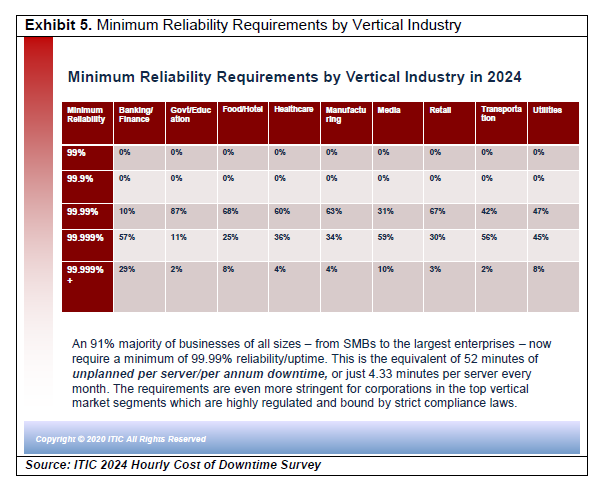
The above industries are highly regulated and incorporate strict compliance laws. But even without regulatory oversight the top vertical market segments are highly visible. Their business operations demand near flawless levels of uninterrupted, continuous operation. In the event of an unplanned outage of even a few minutes, when users cannot access data and applications, business stops and productivity ceases.
These statistics reinforce what everyone knows: infrastructure, security, data access and data privacy and adherence to regulatory compliance are all imperative.
Server hardware, server OS and application reliability all have direct and far-reaching consequences on the corporate bottom line and ongoing business operations. Unreliable and unavailable server hardware, server operating systems and applications will irreparably damage companies’ reputation.
In certain extreme cases, business, and monetary losses because of unreliable servers can cause an enterprise to miss its quarterly or annual revenue forecasts or even go out of business as a direct consequence of sustained losses and litigation brought on by the outage.
Minimum Reliability Requirements Increase Year over Year
Time is money. Time also equates to productivity and the efficiency and continuity of ongoing, uninterrupted daily operations. If any of these activities are compromised by outages for any reason – technical or operational failure that renders the systems and the data unavailable – business grinds to a halt. This negatively impacts the corporate enterprise. The longer the outage lasts, the higher the likelihood of having a domino effect on the corporation’s customers, business partners and suppliers. This in turn will almost certainly raise Total Cost of Ownership (TCO) and undermine the return on investment (ROI).
High reliability and high availability are necessary to manage the corporation’s level of risk and exposure to liability and potential litigation resulting from unplanned downtime and potential non-compliance with regulatory issues. This is evidenced by corporations’ reliability requirements which have increased every year for the past 11 years that ITIC has polled organizations on these metrics.
Consider the following: in 2008, the first year that ITIC surveyed enterprises on their Reliability requirements, 27% of businesses said they needed just 99% uptime; four-in-10 corporations – 40% – required 99.9% availability. In that same 2008 survey, only 23% of firms indicated they required a minimum of “four nines” or 99.99% uptime for their servers, operating systems, virtualized and cloud environments, while a seven percent (7%) minority demanded the highest levels of “five nines” – 99.999% or greater availability.
A decade ago, in ITIC’s 2014 Hourly Cost of Downtime poll, 49% of businesses required 99.99% or greater reliability/uptime; this is an increase of 39% percentage points in the last six years to the present fall 2020. Four nines – 99.99%+ and greater reliability are mission-critical are now the minimum standard for reliability. In our latest 2020 survey – none – 0%- of survey respondents indicated their organizations could live with just “two nines” – 99% uptime or 88 hours of annual unplanned per server downtime!
As Exhibit 5 illustrates, “four nines” or 99.99% uptime and availability is the average minimum requirement for 88% of organizations. However, more and more companies – an overall average of 25% of respondents across all vertical industries as of November 2020 say their businesses now require “five nines” or 99.999% server and operating system uptime. This equates to 5.26 minutes of per server/per annum unplanned downtime. And three percent (3%) of leading-edge businesses need “six nines” 99.9999% near-flawless mainframe class fault tolerant server availability of 31.5 seconds per server/per month.
Increasingly many organizations have even more stringent reliability needs. Requirements of “five and six nines” – 99.999% and 99.9999% – reliability and availability are becoming much more commonplace among all classes of businesses. The reasons are clear: corporations have no tolerance for downtime. They, their end users, business partners, customers, and suppliers all demand uninterrupted access to data and applications to conduct business 24 x7 irrespective of geographic location.
Security Attacks: End Users are Biggest Culprits in Downtime
ITIC’s latest survey results found that security issues and end user carelessness were among the top causes of unplanned system and network downtime in 20202 ITIC expects this trend to continue throughout 2021 and beyond as organized hackers launch ever more sophisticated and pernicious targeted attacks.
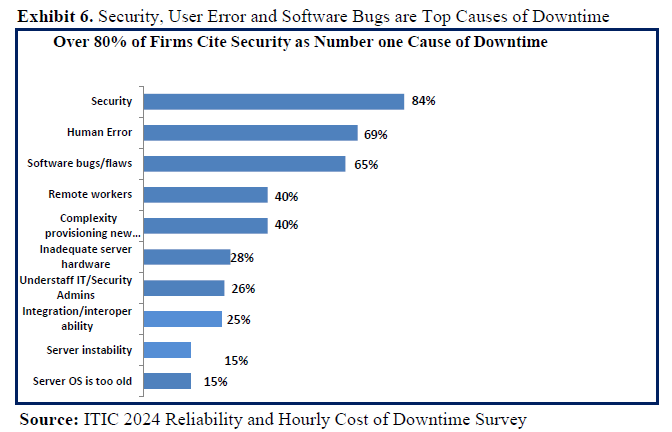
- Security attacks – including targeted attacks by organized hackers, Ransomware attacks, Phishing and Email scams and CEO fraud hacks – now rank as the top cause of downtime, according to 84% of ITIC survey respondents (See Exhibit 6)
- User Error– is also increasingly contributing to corporate downtime and is now rated among the top three causes of company outages along with software flaws/bugs, according to 69% of ITIC survey respondents. End user carelessness encompasses everything from company employees being careless with and losing their own and company owned BYOD devices like laptops, tablets, and mobile phones. Many users fail to properly secure their devices and when they’re lost or stolen, the intellectual property (IP) and sensitive data is easily accessible to prying eyes and thieves. End user carelessness also manifests itself in other ways: many naïve users click on bad links and fall prey to Phishing scams, CEO fraud and leave themselves and their company wide open to security hacks.
The percentage of enterprises unable to calculate the hourly cost of downtime consistently outpaces those that had the ability to estimate downtime costs over the last 10 years. Of the 39% that responded “Yes” only 42% – can make detailed downtime estimates. Only 22% of organizations, or approximately one in five, can accurately assess the hourly cost of downtime and its impact on productivity, daily operations/transactions and the business’ bottom line.
Consequences of Downtime
There is never an opportune time for an unplanned network, system, or service failure. The hourly costs associated with downtime paint a grim picture. But to reiterate, they do not tell the whole story of just how devastating downtime can be to the business’ bottom line, productivity, and reputation.
The ITIC survey data revealed that although monetary losses topped users’ list of downtime concerns, it was one of several factors worrying organizations. The top five business consequences that concerned users are (in order):
- Transaction/sales losses.
- Lost/damaged data.
- Customer dissatisfaction.
- Restarting/return to full operation.
- Regulatory compliance exposure.
The National Archives and Records Administration statistics indicate that 93% of organizations that experience a data center failure go bankrupt within a year.
Consider these scenarios:
- Healthcare: A system failure during an operation could jeopardize human lives. Additionally, targeted hacks by organized groups of professional “black hat” hackers increasingly seek out confidential patient data like Social Security numbers, birth records and prescription drug information. Healthcare is one of the most highly regulated vertical industries and the U.S. and other countries’ government agencies worldwide are aggressively penalizing physicians, clinics, hospitals and healthcare organizations that fail to live up to regulatory compliance standards with respect to privacy and security.
- Banking and Finance: Unplanned outages during peak transaction time periods could cause business to grind to a halt. Banks and stock exchanges could potentially be unable to complete transactions such as processing deposits and withdrawals and customers might not be able to access funds in ATM machines. Brokerage firms and stock exchanges routinely process millions and even billions of transactions daily. The exchanges could lose millions of dollars if transactions or trading were interrupted for just minutes during normal business hours. Financial institutions and exchanges are also among the most heavily regulated industries. Any security breaches will be the subject of intense scrutiny and investigation.
- Government Agencies: A system failure within the Social Security Administration (SSA) that occurs when the agency is processing checks could result in delayed payments, lost productivity and require administrators to spend hours or days in remedial action.
- Manufacturing: The manufacturing vertical is one of the top verticals targeted by hackers, surpassing the healthcare industry. According to the US National Center for Manufacturing Sciences (NCMS), 39% of all cyber-attacks in 2016 were against the manufacturing industry. Since January of 2017 and continuing to the present, March 2024, attacks against manufacturing firms are up 38% thanks to technologies like Machine Learning (ML), Artificial Intelligence (AI) and IoT. Manufacturers are often viewed as “soft targets” or easy entry points of entry into other types of enterprises and even government agencies. Efficiency and uninterrupted productivity are staples and stocks in trade in the manufacturing arena. Any slips are well documented and usually well publicized. The manufacturing shop floor has a near total reliance on robotics and machines and automated networks to get the job done. There are literally thousands of potential entry points – or potential vulnerability points into the network. The implementation of industrial control systems (ICS), centralized command centers that control and connect processes and machines, and the Internet of Things (IoT) external device integration like cameras and robotics, add multiple points of process failure and access points with possible wormholes allowing hackers to infiltrate larger networks.
- Retail: Retailers and sales force personnel trying to close end-of-quarter results would be hard pressed if an outage occurred, which rendered them unable to access or delay access to order entries, the ability to log sales and issue invoices. This could have a domino effect on suppliers, customers, and shareholders.
- Travel, Transportation and Logistics (TT&L): An outage at the Federal Aviation Administration’s (FAA) air traffic control systems could cause chaos: air traffic controllers would find it difficult to track flights and flight paths, raising the risk of massive delays and in a worst-case scenario, airborne and even runway collisions. An airlines reservation system outage of even a few minutes would leave the airlines unable to process reservations and issue tickets and boarding passes via online systems. This scenario has occurred several times in the past several years. Just about every major airline has experienced costly outages over the last five years; this continues to the present day. A June 2019 report released by the U.S. General Accounting Office (GAO) confirmed that 34 airline IT outages that occurred over a three-year span encompassing the years 2015 through 2018. According to the GAO “about 85% of these led to flight delays or cancellations. In 2023 and 2024, the aviation industry has been hit hard by flight cancellations and delays due to faulty aircraft components before and during flights. This almost always results in a domino effect that impacts other businesses and causes supply chain disruptions. Additionally, the U.S. Department of Transportation’s 2023 Annual Transportation Statistics Annual Report[1] noted the entire U.S. transportation system vulnerable to cyber and electronic disruptions. This is particularly true in the aviation system, which is dependent on electronic and digital navigation aids, communication systems, command and control technologies, and public information systems. Outages and cybersecurity issues also plague other transportation sectors like the trucking and auto industry. Cyber incidents pose a variety of threats to transportation systems. Cyber vulnerabilities have been documented in multimodal operational systems, control centers, signaling and telecommunications networks, draw bridge operations, transit and rail operations, pipelines, and other existing and emerging technologies. State and local governments face growing threats from hackers and cybercriminals, including those who use ransomware software that hijacks computer systems, encrypts data, and locks machines, holding them hostage until victims pay a ransom or restore the data on their own. In February 2018 hackers struck the Colorado Department of Transportation in two ransomware attacks that disrupted operations for weeks. State officials had to shut down 2,000 computers, and transportation employees were forced to use pen and paper or their personal devices instead of their work computers. A 2021 Report by SOTI, a global management firm headquartered in Ontario, Canada found that in the trucking industry “…When trucks are on the road, T&L companies make money. When they’re not, they’re losing money due to the cost of downtime which averages $448 to $760 USD per vehicle per day.”
When downtime occurs, business grinds to a halt, productivity is impaired and the impact on customers follows almost immediate. Aside from the immediate consequences of being unable to conduct business and loss of revenue, unreliable systems also undermine quality of service, potentially causing firms to be unable to meet SLA agreements. This can lead to breach of contract, cause the company to lose business and customers, and put it at risk for expensive penalties and litigation. Even in the absence of formal litigation, many organizations will offer their customers, business partners and suppliers some goodwill concessions in the form of future credits or discounts for inconvenience and as a way of retaining the business and mitigating the damage to the company’s reputation. These goodwill actions/concessions, while advisable, inevitably affect the corporate bottom line.
Conclusions
The hourly cost of downtime will continue to rise. Downtime of any duration is expensive and disruptive. When a mission critical application, server or network is unavailable for even a few minutes, the business risks increase commensurately. They include:
- Lost productivity.
- Lost, damaged, destroyed, changed or stolen data.
- Damage to the company’s reputation potentially can result in lost business.
- Potential for litigation by business partners, customers, and suppliers.
- Regulatory compliance exposure.
- Potential for civil, criminal liabilities, penalties and even jail time for company executives.
- Potential for unsustainable losses which can result in companies going out of business.
All these issues create pressure on organizations and their IT and security departments to ensure very high levels of system availability and avoid outages at all costs. Some 90% of businesses now require a minimum of 99.99% or greater system and network availability. Additionally, in 2024, 44% of companies say they strive for 99.999% uptime and availability which is the equivalent of 5.26 minutes of per server annual unplanned downtime. ITIC anticipates that these numbers will continue to increase.
If the network or a critical server or application stops, so does the business.
Ensuring network availability is challenging in today’s demanding business environment. Mission critical servers and crucial line of business applications are increasingly located or co-located in public and hybrid cloud environments. Cloud deployments are almost exclusively virtualized, with multiple instances of mission critical applications housed in a single server. Without proper management, security and oversight, there is the potential for higher collateral damage in the event of any unplanned outage or system disruption.
Additional risk of downtime is also posed by the higher number of devices that are interconnected via IoT networks utilizing Analytics, BI and AI. IoT networks facilitate communications among applications, devices, and people. In IoT ecosystems in which devices, data, applications, and people are all interconnected, there is a heightened risk of collateral damage and potential security exposures in the event of an unplanned outage.
Technologies like cloud, virtualization, mobility, BYOD, IoT, Analytics, BI, AI and AIOps all deliver tangible business and technology benefits and economies of scale that can drive revenue and lower Total Cost of Ownership (TCO) and accelerate Return on Investment (ROI). But they are not fool proof and there are no panaceas.
In many businesses – mobility – whether because of employee travel or working remotely – is commonplace. BYOD usage is also common. Employees routinely use their personal mobile devices as well as company owned laptops, tablets, smart phones, and other devices to access the corporate data networks remotely. IT administrators have more devices to monitor, larger and more complex applications to provision and monitor and more endpoints and network portals to secure. Many enterprise IT shops are under-staffed and overworked. And many SMBs firms with 20, 50 or even 100 employees may have limited, part-time or even no dedicated onsite IT or security administrators.
Time is money.
To reiterate, downtime will almost certainly have a negative impact on companies’ relationships with customers, business suppliers and partners.
To minimize downtime, increase system, network availability corporations, and minimize risk enterprises must ensure that robust reliability is an inherent feature in all servers, network connectivity devices, applications, and mobile devices. This requires careful tactical and strategic planning to construct a solid business and technology strategy. A crucial component of this strategy is to deploy the appropriate device and network security and monitoring tools. Every 21st Century network environment needs robust security on all of its core infrastructure devices and systems (e.g., servers, firewalls, routers, etc.) and continuous, comprehensive end-to-end monitoring for complex, distributed applications in physical, virtual and cloud environments.
In summary, it is imperative that companies of all sizes and across every vertical market discipline thoroughly review every instance of downtime and estimate all the associated monetary costs; the impact on internal productivity; remediation efforts and the business risk to the organization. Companies should also determine whether customers, suppliers and business partners experienced any negative impact, e.g. unanticipated downtime, lost productivity/lost business, security exposures because of the outage.
All appropriate corporate stakeholders from the C-suite executives; IT and security administrators; department heads and impacted workers should have a hand in correctly calculating the hourly cost of downtime. Companies should then determine how much downtime and risk the corporation can withstand.
It is imperative that all businesses from micro SMBs to the largest global enterprises calculate the cost of employee and IT and security administrative time in terms of monetary and business costs. This includes the impact on productivity; data assets as well as the time it takes to remediate and restore the company to full operation. Companies must also fully assess and estimate how much risk their firms can assume, including potential liability for municipal, state, federal and even international regulatory compliance laws.
[1] U.S. Department of Transportation, “Transportation Statistics Annual Report 2023,” Pg. 1 -39, URL: https://www.bts.gov/sites/bts.dot.gov/files/2023-12/TSAR-2023_123023.pdf
ITIC 2024 Hourly Cost of Downtime Part 2 Read More »